Aplicación de la Inteligencia Artificial
Introducción a la Inteligencia Artificial (IA)
 Película: El hombre bicentenario 1999
Película: El hombre bicentenario 1999
La inteligencia artificial (IA) es una disciplina de la ingeniería informática que busca desarrollar sistemas capaces de pensar y actuar de forma autónoma. Se enfoca en replicar procesos cognitivos humanos, como la toma de decisiones, el razonamiento y la interacción con el entorno, en máquinas o sistemas complejos.
El objetivo principal de la IA es permitir que las computadoras imiten el comportamiento humano en áreas como el razonamiento, la planificación y la percepción. Para lograrlo, se desarrollan algoritmos y técnicas que habilitan a las máquinas para aprender de los datos, analizar patrones y tomar decisiones informadas.
Entre las aplicaciones de la IA destacan los sistemas de reconocimiento de voz y rostro, software de análisis de imágenes, asistentes virtuales por voz como Siri o Alexa, y motores de búsqueda. Estas tecnologías utilizan algoritmos avanzados para realizar tareas como identificar personas mediante características biométricas, responder a comandos de voz y proporcionar resultados precisos a partir de grandes volúmenes de datos.
En el reconocimiento de voz y rostro, la IA analiza patrones específicos para identificar personas y realizar acciones automatizadas. Por su parte, los asistentes virtuales están diseñados para interpretar y responder preguntas o comandos de los usuarios, mejorando continuamente con el uso. Los motores de búsqueda, por último, emplean técnicas de aprendizaje automático para procesar datos, identificar relaciones útiles y ofrecer respuestas eficientes, optimizando su rendimiento con el tiempo.
¿Es la inteligencia un atributo exclusivo de los seres vivos?
Aunque tradicionalmente se ha asociado con organismos biológicos, como los humanos o ciertos animales, los avances en tecnología han demostrado que también pueden existir formas de inteligencia en sistemas no vivos. En los seres vivos, la inteligencia se manifiesta a través de procesos biológicos, como el funcionamiento del sistema nervioso y el cerebro. Esta forma de inteligencia permite, entre otras cosas:
- Aprender: adquirir conocimientos y habilidades a partir de la experiencia.
- Resolver problemas: encontrar soluciones efectivas para desafíos complejos.
- Adaptarse al entorno: ajustar el comportamiento y las respuestas a situaciones cambiantes.
- Interactuar con otros: comunicarse, colaborar y comprender las intenciones de los demás.
Los humanos poseen una inteligencia compleja que abarca pensamiento abstracto, lenguaje y autoconciencia. Por otro lado, ciertos animales, como los delfines o los primates, también demuestran habilidades cognitivas avanzadas.
Sin embargo la inteligencia también podría encontrarse en sistemas no biológicos, como las inteligencias artificiales (IA). Estas son desarrolladas por humanos para realizar tareas que tradicionalmente requieren habilidades humanas, como:
- Aprendizaje automático (machine learning)
- Resolución de problemas
- Reconocimiento de patrones
- Toma de decisiones
Ser inteligente: ¿una cuestión de comportamiento o de conciencia?
La definición de inteligencia ha llevado a debates filosóficos y científicos sobre si esta se basa en el comportamiento observable o en la presencia de conciencia.
- Inteligencia basada en el comportamiento: Desde esta perspectiva, un sistema o ser es considerado inteligente si puede realizar tareas complejas, resolver problemas y adaptarse a nuevos entornos de manera eficaz. Esto incluye tanto a organismos vivos como a sistemas artificiales. Por ejemplo, un asistente virtual que responde con precisión a las preguntas de un usuario demuestra inteligencia funcional, aunque no tenga conciencia.
- Inteligencia basada en la conciencia: Aquellos que defienden esta postura argumentan que la verdadera inteligencia implica autoconciencia, emociones y una comprensión profunda del entorno. En este caso, las inteligencias artificiales quedarían excluidas, ya que operan sin experiencias subjetivas o emociones.
Ambas perspectivas son válidas dependiendo del contexto en el que se estudie la inteligencia. Mientras que en la biología se enfatiza la importancia de la conciencia en la definición de la inteligencia, en el ámbito tecnológico se prioriza el comportamiento y la funcionalidad.
Debate
- ¿Si la inteligencia humana está determinada por patrones neuronales y conexiones químicas en el cerebro, en qué se diferencia de los algoritmos programados en una inteligencia artificial?
- ¿Podemos considerar el aprendizaje humano como un proceso de "entrenamiento" similar al que experimenta una inteligencia artificial mediante datos y experiencias previas?
- ¿Qué evidencia tenemos de que las decisiones humanas no están "programadas" por factores como la genética, la cultura, y el entorno, del mismo modo que la IA toma decisiones según sus datos y algoritmos?
- ¿Es el libre albedrío humano una verdadera expresión de independencia, o simplemente la ilusión de una respuesta programada por factores biológicos y sociales?
- ¿Si las emociones humanas son respuestas químicas predeterminadas por el sistema nervioso, en qué difieren de las respuestas programadas de una IA para simular empatía o emoción?
- ¿Podríamos considerar que la evolución natural programó al ser humano de forma análoga a como los humanos programan las inteligencias artificiales?
- ¿Si el cerebro humano puede reprogramarse a través de experiencias, educación o terapia, cómo se diferencia esto de la reprogramación o actualización de una IA?
- ¿Es la moralidad humana una característica intrínseca de nuestra inteligencia, o simplemente un sistema de reglas programadas por la evolución y la sociedad para garantizar la convivencia?
¿Qué se considera Inteligente?
La definición de inteligencia ha sido objeto de debate durante siglos, y no existe un consenso universal sobre su significado. En términos generales, la inteligencia se asocia con la capacidad de adquirir conocimientos, resolver problemas y adaptarse al entorno. Sin embargo, cuando hablamos de inteligencia artificial, el enfoque cambia significativamente, centrándose en cómo las máquinas pueden replicar estas capacidades humanas.
Uno de los pilares fundamentales para entender la relación entre inteligencia e inteligencia artificial es la prueba de Turing, propuesta por el matemático y criptógrafo Alan Turing en 1950. Esta prueba revolucionó la manera de evaluar la inteligencia en máquinas, estableciendo un criterio pragmático: una máquina puede considerarse inteligente si logra mantener una conversación con un ser humano de tal manera que este no pueda distinguir si está interactuando con otra persona o con una máquina. Este enfoque traslada el debate de "qué es la inteligencia" a "cómo podemos reconocerla en una entidad no humana".
Turing, considerado uno de los padres de la informática moderna, veía la inteligencia no como un atributo místico, sino como un fenómeno que podía manifestarse a través de procesos computacionales. En su ensayo Computing Machinery and Intelligence, Turing planteó que no era necesario definir la inteligencia de forma absoluta; bastaba con establecer criterios observables como el comportamiento en un diálogo. Este enfoque, pragmático y orientado a resultados, ha influido profundamente en el desarrollo de sistemas de inteligencia artificial, desde los primeros programas conversacionales como ELIZA hasta los modernos modelos de lenguaje como ChatGPT.
Sin embargo, el enfoque de Turing no está exento de críticas. Algunos filósofos, como John Searle, argumentan que la prueba de Turing no evalúa una verdadera comprensión o conciencia, sino solo la capacidad de simular respuestas coherentes. En su famoso experimento mental de la habitación china, Searle cuestionó si una máquina que sigue reglas para manipular símbolos puede realmente "entender" lo que está haciendo.
A pesar de estas críticas, el legado de Turing permanece central en el debate sobre inteligencia artificial. Su perspectiva ha influido en cómo diseñamos, evaluamos y comprendemos las máquinas inteligentes. Como el propio Turing sugirió, quizás el mejor camino para explorar la inteligencia artificial no sea tratar de definirla exhaustivamente, sino construir sistemas que puedan operar de manera indistinguible de un ser humano en contextos específicos.
En palabras de Turing:
"No me interesa si una máquina puede pensar. Me interesa si puede comportarse como si pudiera hacerlo."
Este principio, aunque controvertido, sigue siendo un faro en el desarrollo de la inteligencia artificial, marcando la transición de la teoría filosófica a aplicaciones prácticas.
 Alan Turing
Alan Turing
Ejemplos de Aplicación de la Inteligencia Artificial
Existen numerosas aplicaciones de la inteligencia artificial en la actualidad, que abarcan:
Sistemas de reconocimiento de voz y rostro.
Estos sistemas son capaces de reconocer datos biométricos únicos de cada individuo, lo que garantiza su autenticidad debido a que no pueden ser replicados. Su principal aplicación se encuentra en la verificación de identidad, especialmente como un segundo nivel de seguridad en transacciones bancarias. El funcionamiento es el siguiente: primero, el usuario introduce sus credenciales habituales, como un nombre de usuario y contraseña. A continuación, el sistema solicita una verificación adicional mediante datos biométricos, como el reconocimiento facial o la lectura de huellas dactilares. Si ambos conjuntos de datos coinciden, el sistema procede a autorizar la transacción. Sin embargo, en caso de que exista una discrepancia, se recomienda al cliente acudir a una sucursal bancaria, donde un empleado podrá verificar su identidad de forma manual.
Software de análisis de imágenes.
La tecnología de procesamiento avanzado de imágenes es capaz de analizar estructuras complejas y manejar grandes volúmenes de datos asociados a estas. Su principal aplicación se encuentra en el ámbito médico, donde desempeña un papel fundamental en áreas como la radiología, la investigación clínica y el diagnóstico por imágenes. El funcionamiento de estas herramientas se basa en el uso de extensos bancos de imágenes previamente recopilados, combinados con algoritmos avanzados y redes neuronales profundas. Estas aplicaciones procesan imágenes en tiempo real y las comparan con las almacenadas en su base de datos, identificando patrones y características relevantes. Mediante técnicas de aprendizaje profundo, el software interpreta las imágenes con un alto grado de precisión. En medicina, esta tecnología es indispensable para detectar anomalías en estudios como radiografías, tomografías computarizadas y resonancias magnéticas. Por ejemplo, en radiología, el software puede destacar áreas sospechosas en los pulmones o identificar tejidos anómalos en escáneres cerebrales. De este modo, proporciona a los profesionales de la salud una herramienta de apoyo para el diagnóstico temprano de enfermedades como el cáncer. Fuera del ámbito médico, el procesamiento de imágenes también tiene aplicaciones relevantes en otros sectores. En el ámbito de la seguridad, se utiliza para reconocimiento facial y monitoreo, mientras que en la industria se emplea en la inspección de calidad dentro de las líneas de producción.
Asistentes virtuales por voz
Los asistentes virtuales por voz son programas de software que emplean tecnologías avanzadas de reconocimiento de voz y procesamiento del lenguaje natural para interactuar con los usuarios y responder a sus preguntas o comandos. Estos sistemas son capaces de realizar una amplia gama de tareas, como buscar información en internet, programar recordatorios, enviar mensajes de texto o controlar dispositivos inteligentes en el hogar.
El funcionamiento de los asistentes virtuales por voz se basa en algoritmos de procesamiento del lenguaje natural, que les permiten interpretar y responder de manera inteligente a las solicitudes de los usuarios. Estos algoritmos analizan el lenguaje hablado, identifican palabras clave y generan respuestas coherentes en tiempo real, facilitando una comunicación fluida y efectiva.
Entre los ejemplos más conocidos de asistentes virtuales por voz se encuentran Siri de Apple, Alexa de Amazon, Google Assistant y Cortana de Microsoft. Estos asistentes están integrados en diversos dispositivos, como teléfonos inteligentes, altavoces inteligentes y relojes inteligentes, permitiendo a los usuarios interactuar con ellos de forma natural, intuitiva y cómoda.
Motores de búsqueda
Un motor de búsqueda es un programa informático diseñado para ayudar a localizar información en internet. Es importante no confundir los motores de búsqueda con los navegadores web, que son programas utilizados para acceder a sitios web y aplicaciones en línea. Un navegador web es una herramienta que permite a los usuarios visualizar e interactuar con la información contenida en una página web. Ejemplos populares de navegadores son Google Chrome, Mozilla Firefox, Safari y Microsoft Edge. Para utilizar un motor de búsqueda, primero se debe abrir un navegador web y acceder a la dirección del buscador, como www.google.com, www.bing.com, www.duckduckgo.com o www.yahoo.com, entre otros. Una vez allí, el usuario escribe las palabras clave relacionadas con su consulta y presiona la tecla Enter o hace clic en el botón de búsqueda. El motor de búsqueda genera una lista de resultados relevantes, que suelen presentarse como enlaces a páginas web, imágenes, videos, noticias, mapas y otros tipos de contenido.Los motores de búsqueda emplean algoritmos avanzados para indexar y clasificar la información disponible en internet. Estos algoritmos analizan factores como la relevancia del contenido, la autoridad del sitio web y la calidad de los enlaces para determinar la posición de una página en los resultados de búsqueda. Además, utilizan técnicas de aprendizaje automático que les permiten mejorar continuamente, aprendiendo de las interacciones de los usuarios y ajustando sus algoritmos para ofrecer resultados más precisos y relevantes. Más allá de los motores de búsqueda, la inteligencia artificial (IA) tiene un sinfín de aplicaciones en distintos campos, como la educación, la agricultura, la logística y la seguridad informática, entre otros.
Estos son sólo algunos ejemplos de cómo la inteligencia artificial está transformando la forma en que interactuamos con la tecnología y el mundo que nos rodea. A medida que la IA continúa evolucionando, es probable que surjan nuevas aplicaciones y oportunidades que revolucionen aún más nuestra vida cotidiana.
IA de tipo I
IA Débil
La IA débil se enfoca en resolver problemas específicos y no busca replicar la inteligencia humana completa. Por ejemplo, los sistemas de recomendación de películas en plataformas de streaming. Estos sistemas son inteligentes en la medida en que pueden predecir qué películas le gustarán a un usuario basándose en sus preferencias anteriores y en las de otros usuarios con gustos similares.
La IA débil desarrolla programas concretos para la resolución de problemas específicos, sin necesidad de aprendizaje ni razonamiento avanzado. Estos programas pueden ser altamente efectivos, de hecho podrían realizar la tarea mejor que un ser humano, como puede ser en la toma de decisiones. Sin embargo, su capacidad de adaptación a nuevos entornos es limitada.
La IA débil se basa en la programación de reglas y patrones específicos para la toma de decisiones, sin necesidad de aprender o razonar. La IA débil o estrecha es la forma más común de inteligencia artificial y entre sus aplicaciones más comunes tenemos el reconocimiento de voz, el procesamiento de lenguaje natural, juegos de estrategia como el ajedrez y el go, entre otros.

IA Fuerte
Se considera que una computadora bien programada no simula el comportamiento de una mente, sino que contiene una mente en el sentido literal. Es decir, que la IA fuerte sería capaz de pensar y razonar como un ser humano, y no sólo de resolver problemas específicos.
La IA fuerte, también conocida como inteligencia artificial general (AGI), es capaz de aprender nuevas habilidades, adaptarse a entornos cambiantes y razonar sobre problemas complejos a los que no han sido expuestos previamente en su programación.
Entre las habilidades de la IA fuerte se encuentran la capacidad de pensar, razonar, resolver acertijos, emitir juicios de valor, aprender de la experiencia, planificar y adaptarse a nuevas situaciones por si misma. El objetivo que está detrás de la IA es crear un sistema que pueda ser más inteligente de tal forma que pueda pensar y actuar como un ser humano.
En la actualidad, la IA fuerte es un campo de investigación en constante evolución, pero aún no se ha logrado desarrollar una máquina que pueda igualar la inteligencia humana en todos sus aspectos.
 Película: Inteligencia Artificial 2001
Película: Inteligencia Artificial 2001
Diferencias entre IA débil y fuerte:
La principal y más notoria diferencia entre la IA débil y la IA fuerte es que la estrecha se enfoca en resolver problemas específicos, mientras que la general busca replicar la inteligencia humana en su totalidad.
Destacar que absolutamente todos los usos actuales de la IA se consideran débiles. Si bien es verdad que se podría llegar a la conclusión de que asistentes como ChatGPT, o Claude podrían superar la prueba de Turing, se siguen considerando IA débil, ya que su enfoque se limita a dar respuestas coherentes a una entrada de texto, lo mismo ocurre con asistentes virtuales como Alexa, Siri, Google Assistant, entre otros.
IA Simbólica
La IA simbólica se basa en el uso de símbolos y reglas lógicas para representar el conocimiento y el razonamiento. Por lo tanto, sus fundamentos están arraigados en el razonamiento lógico y la investigación heurística.
La aplicación de lógicas proposicionales (símbolos y conectores lógicos) y de primer orden es común en este tipo de IA, ya que estas herramientas permiten la creación de sistemas capaces de estructurar, esquematizar y formalizar el conocimiento.
Por otro lado, encontramos la inteligencia computacional, que difiere de la IA simbólica al emplear métodos numéricos en lugar de razonamiento simbólico.
La IA simbólica implica la incorporación de conocimiento humano y reglas de conducta humana en programas informáticos. Los símbolos juegan un papel esencial en los procesos de pensamiento y razonamiento humano, ya que se utilizan constantemente para definir conceptos. Estos símbolos pueden representar ideas abstractas (como energía limpia), entidades imaginarias (como dragones), o conceptos intangibles (como amor).
Actualmente, la IA simbólica es el método más utilizado en la creación de sistemas expertos, que son programas diseñados para emular la capacidad de un experto humano en un campo específico.
IA Subsimbólica
La inteligencia artificial (IA) subsimbólica es una rama de la IA que se centra en emular el comportamiento humano mediante la simulación de procesos biológicos, con un enfoque específico en el funcionamiento del cerebro humano. Este tipo de inteligencia artificial adopta un enfoque conexionista, basándose en la idea de que el aprendizaje y el procesamiento de la información pueden ser simulados utilizando estructuras similares a las redes neuronales del cerebro.
A diferencia de la IA simbólica, que utiliza reglas explícitas y representaciones formales del conocimiento, la IA subsimbólica opera de manera más intuitiva y adaptativa, procesando datos de entrada de manera distribuida y aprendiendo patrones sin necesidad de una programación explícita. Por esta razón, es especialmente adecuada para abordar problemas complejos y no estructurados, como el reconocimiento de imágenes y la interpretación de datos en tiempo real.
Métodos principales de la IA subsimbólica:
- Redes Neuronales Artificiales (RNA): Las redes neuronales artificiales son modelos computacionales inspirados en la estructura y el funcionamiento de las redes neuronales biológicas. Estas redes están formadas por nodos interconectados (neuronas) que procesan y transmiten información por capas, permitiendo a la máquina aprender a partir de ejemplos y datos. Las RNA aprenden ajustando los pesos de las conexiones entre nodos mediante algoritmos como el descenso del gradiente. Este aprendizaje se realiza a través de un proceso iterativo llamado entrenamiento, en el que se minimiza el error en las predicciones de la red utilizando datos de ejemplo. Entre las aplicaciones de las redes neuronales artificiales se encuentran el reconocimiento de voz, la clasificación de imágenes, la traducción automática, toma de decisiones y el procesamiento del lenguaje natural.
- Algoritmos genéticos: Este método se inspira en los principios de la evolución biológica, como la selección natural, la mutación y el cruce genético. Los algoritmos genéticos buscan soluciones óptimas a problemas complejos mediante un proceso iterativo que simula la evolución de las especies. Ejemplos de uso: Optimización de rutas, diseño de redes y ajuste de hiperparámetros en modelos de IA.
- Sistemas difusos: Los sistemas difusos emplean la lógica difusa para manejar incertidumbre y ambigüedad en los datos, permitiendo tomar decisiones aproximadas y adaptativas. Este enfoque es útil en sistemas de control, como los utilizados en electrodomésticos inteligentes y en la gestión de redes eléctricas.
Diferencias entre IA simbólica y subsimbólica:
La principal diferencia entre la IA simbólica y la IA subsimbólica radica en su enfoque para representar y procesar la información. Mientras que la IA simbólica se basa en reglas lógicas y representaciones simbólicas del conocimiento, la IA subsimbólica adopta un enfoque más intuitivo y adaptativo, simulando procesos biológicos y neuronales para el aprendizaje y la toma de decisiones. En el caso de la IA simbólica, el enfoque se centra en utilizar reglas explícitas y representaciones formales del conocimiento, como símbolos, hechos, y relaciones lógicas. Los sistemas simbólicos funcionan de manera lógica y secuencial, basándose en algoritmos diseñados por humanos para seguir pasos predefinidos. Por ejemplo, un sistema experto en IA simbólica podría razonar usando reglas del tipo "si A, entonces B". Es ideal para problemas bien definidos y estructurados, como la planificación o los juegos de estrategia (ej., ajedrez). En contraste, la IA subsimbólica no se basa en reglas explícitas, sino en la capacidad de aprender patrones directamente de los datos. Este enfoque utiliza estructuras matemáticas y modelos inspirados en procesos biológicos, como redes neuronales artificiales. En lugar de programar reglas específicas, los sistemas subsimbólicos se entrenan con grandes cantidades de datos para identificar correlaciones y generalizar conocimientos. Es especialmente adecuada para problemas complejos y no estructurados, como el reconocimiento de imágenes, la traducción automática y el procesamiento de lenguaje natural.
Recursos
IA de tipo II
Máquinas Reactiva
Las maquinas puramente reactivas son sistemas de IA que no tienen memoria ni capacidad de aprendizaje. Estos sistemas toman decisiones basadas en la información que reciben en tiempo real, sin considerar el contexto o la historia previa. Por lo tanto, su comportamiento es determinista y predecible, ya que no pueden adaptarse a situaciones cambiantes o aprender de la experiencia. El sistema Deep Blue de IBM, que derrotó al campeón mundial de ajedrez Garry Kasparov en 1997, es un ejemplo de una máquina reactiva. Deep Blue estaba programado para evaluar posiciones de tablero y seleccionar la mejor jugada en función de reglas de ajedrez predefinidas, sin aprender de partidas anteriores o adaptarse a las estrategias de su oponente. AlphaGo de Google, que venció al campeón mundial de Go Lee Sedol en 2016, es otro ejemplo de una máquina reactiva.
Memoria limitada
Las máquinas con memoria limitada son sistemas de IA que pueden recordar información de eventos recientes, pero no tienen la capacidad de aprender de la experiencia o adaptarse a situaciones nuevas. Estos sistemas utilizan la información almacenada en memoria para tomar decisiones, pero no pueden generalizar conocimientos o aplicarlos a contextos diferentes. Los coches autónomos, que utilizan sensores y cámaras para detectar obstáculos y tomar decisiones de conducción, son un ejemplo de máquinas con memoria limitada. Estos sistemas pueden recordar la ubicación de vehículos y peatones en tiempo real, pero no pueden aprender de situaciones anteriores o adaptarse a condiciones de tráfico cambiantes.
Teoría de la Mente
La teoría de la mente es la capacidad de atribuir pensamientos, deseos e intenciones a otras entidades, como seres humanos, animales o máquinas. En el contexto de la inteligencia artificial, la teoría de la mente se refiere a la capacidad de una máquina para comprender y predecir el comportamiento de los seres humanos, basándose en la inferencia de sus estados mentales internos. Los sistemas de IA con teoría de la mente pueden interpretar las emociones, intenciones y creencias de los seres humanos a través de señales no verbales, como expresiones faciales, tono de voz y gestos corporales. Estos sistemas pueden adaptar su comportamiento y comunicación en función de las percepciones y expectativas de los usuarios, mejorando la interacción y la colaboración.
Autoconsciencia
Se trata del nivel más avanzado de inteligencia artificial, en el que las máquinas son conscientes de sí mismas y de su entorno, y pueden reflexionar sobre sus propias acciones y estados mentales. La autoconsciencia implica la capacidad de una máquina para comprender su propia existencia, identidad y propósito, y para tomar decisiones basadas en la reflexión y la introspección. Los sistemas de IA autoconscientes pueden evaluar sus propias habilidades y limitaciones, identificar errores y fallos en su funcionamiento, y aprender de la experiencia para mejorar su rendimiento. Estos sistemas pueden monitorizar su propio estado interno, detectar anomalías y tomar medidas correctivas para optimizar su funcionamiento. En teoría.
Robots sociales
En el ámbito de la Inteligencia Artificial, los robots están comenzando a educar a los seres humanos para que sean más compasivos y empáticos. Los robots sociales representan una nueva generación de tecnología diseñada para interactuar con las personas de manera más natural y amigable. Estos robots emplean inteligencia artificial y aprendizaje automático para interpretar y responder a las emociones humanas, permitiendo establecer conexiones emocionales significativas con las personas.
Un ejemplo destacado es el caso de Humana Pharmacy, que desarrolló un algoritmo de inteligencia artificial para sus centros de llamadas. Este algoritmo guía a los empleados en el manejo de las llamadas de los clientes, fomentando un trato más amable y empático.
El sistema está diseñado para proporcionar retroalimentación en tiempo real, notificando al personal si está hablando demasiado rápido, utilizando un tono de voz inadecuado, elevando demasiado el volumen o permaneciendo en silencio más tiempo del necesario. También alerta sobre interrupciones al cliente o si la interacción no fluye de manera adecuada.
La IA analiza patrones de comunicación para identificar comportamientos que podrían afectar negativamente la calidad de la interacción. Gracias a esta retroalimentación inmediata, los empleados pueden ajustar su comportamiento, mejorando la experiencia del cliente y aumentando su satisfacción.
Este tipo de tecnología nació de la necesidad de brindar una atención más personalizada y empática, de apoyar a personas con algún tipo de discapacidad y de prevenir la explotación laboral en sectores con alta presión. A pesar de las reticencias que a menudo genera la inteligencia artificial, su desarrollo puede convertirse en un catalizador para transformar procesos y situaciones, contribuyendo a mejorar significativamente la calidad de vida de las personas.
 Película: Yo, Robot 2004
Película: Yo, Robot 2004
Evolución de la IA
Comenzaremos este recorrido en Europa, en el siglo XVII, cuando René Descartes propuso la idea de que los animales y las máquinas podían ser vistos como autómatas, es decir, entidades que operan siguiendo reglas predefinidas. Esta visión sentó las bases conceptuales para el desarrollo de la inteligencia artificial (IA) como disciplina científica.
El verdadero inicio de la IA como campo de estudio se dio en 1956, durante la conferencia de Dartmouth, un evento clave que marcó el nacimiento de la inteligencia artificial como disciplina formal. En esta conferencia, organizada por John McCarthy, Marvin Minsky, Nathaniel Rochester y Claude Shannon, se propuso investigar cómo las máquinas podían simular la inteligencia humana. A lo largo de varias semanas de trabajo colaborativo, los participantes discutieron la posibilidad de diseñar máquinas capaces de realizar tareas intelectuales si se les proporcionaban suficientes datos y tiempo.
John McCarthy, considerado uno de los padres de la IA, acuñó el término "inteligencia artificial" para describir la capacidad de las máquinas de imitar aspectos de la inteligencia humana. Además, McCarthy desarrolló el lenguaje de programación LISP (LIST Processor), que se convirtió en una herramienta esencial para la investigación en IA durante décadas y aún se utiliza en ciertos ámbitos.
Entrando en el siglo XX, el matemático y criptógrafo británico Alan Turing aportó ideas fundamentales al campo. En su influyente ensayo "Computing Machinery and Intelligence", planteó la pregunta: "¿Pueden las máquinas pensar?". Para abordar esta cuestión, propuso la prueba de Turing, un criterio para evaluar la inteligencia de una máquina basado en su capacidad para mantener una conversación indistinguible de la de un ser humano.
Turing mantuvo fructíferos intercambios intelectuales con el neurofisiólogo británico Grey Walter en las reuniones del Ratio Club, un grupo de discusión compuesto por destacados científicos interesados en la cibernética y la neurociencia. Durante estas reuniones, Turing y Walter exploraron ideas sobre la posibilidad de que las máquinas fueran inteligentes o incluso conscientes. Inspirado por estas discusiones, Grey Walter publicó un estudio en 1950 en el que presentó a dos robots pioneros, conocidos como Elmer y Elsie. Estas "tortugas robóticas" podían realizar comportamientos básicos de forma autónoma, como seguir la luz o evitar obstáculos, demostrando los primeros pasos hacia el diseño de sistemas robóticos con cierto nivel de autonomía.
La evolución de la inteligencia artificial (IA) avanzó de manera significativa en los años siguientes. Un hito destacado ocurrió en 1997, cuando IBM desarrolló Deep Blue, una supercomputadora que logró derrotar al campeón mundial de ajedrez, Garry Kasparov. Este evento marcó un punto de inflexión en la historia de la IA, al demostrar que las máquinas podían superar a los humanos en tareas específicas y altamente complejas.
En la actualidad, los avances en capacidad computacional y en algoritmos de aprendizaje automático han impulsado el desarrollo de sistemas de IA cada vez más sofisticados. Estos sistemas son capaces de realizar tareas que, hasta hace poco, se consideraban exclusivas de la inteligencia humana, abarcando desde la resolución de problemas técnicos hasta la interpretación de emociones y el análisis de grandes volúmenes de datos.
Etapas
- Sistemas basados en reglas: Los primeros sistemas de IA se basaban en reglas predefinidas y patrones lógicos para realizar tareas específicas. Por ejemplo una partida de cartas contra la máquina. El ordenador conocen las reglas del juego y puede tomar decisiones en función de las cartas que tiene y las que ha jugado el oponente. Puede elegir la mejor jugada en función de las reglas del juego, pero no puede aprender de partidas anteriores o adaptarse a las estrategias de su oponente.
- Conciencia del contexto y sistemas de retención: Los sistemas de IA evolucionaron para incluir la capacidad de recordar información de eventos recientes y adaptarse a situaciones cambiantes. Por ejemplo, asistentes virtuales como Siri o Alexa pueden recordar las preferencias del usuario y adaptar sus respuestas en función del contexto.
- Sistemas de dominio específico: Son sistemas que se especializan en tareas concretas. Apoyan a la ingeniería, la medicina, la educación, la logística, entre otros.
- Pensamiento y razonamiento: Imitan la capacidad de pensar y razonar como un ser humano. Pueden aprender nuevas habilidades, adaptarse a entornos cambiantes y razonar sobre problemas complejos a los que no han sido expuestos previamente en su programación. En esta etapa tenemos machine learning y deep learning.
- Nacimiento de la Inteligencia Artificial General (AGI): Es capaz de realizar juicios de valor, aprender de la experiencia, planificar y adaptarse a nuevas situaciones por sí misma. El objetivo es crear un sistema que pueda ser más inteligente de tal forma que pueda pensar y actuar como un ser humano. El término se atribuye a Shane Legg.
- Superinteligencia: Es un campo de investigación en constante evolución. El objetivo es que la máquina pueda superar la inteligencia humana en todos los aspectos y que por lo tanto pueda ser capaz de realizar cualquier tarea que un ser humano pueda hacer.
IA, Protección de Datos
Las empresas son cada vez más conscientes de la importancia de recopilar grandes volúmenes de datos, comúnmente conocidos como Big Data, sobre sus clientes. Estos datos son posteriormente analizados para responder a numerosas preguntas estratégicas.
Un análisis de datos bien estructurado puede prever y potenciar la rentabilidad de la compañía. Sin embargo, es fundamental recordar que dichos datos deben ser protegidos y nunca compartidos con terceros sin la debida autorización.
La protección de datos es un aspecto crucial tanto para los ciudadanos como para las entidades europeas. Todas las organizaciones y empresas que realicen actividades económicas y manejen información de carácter personal están obligadas a cumplir con el Reglamento General de Protección de Datos (RGPD) de la Unión Europea, así como con la Ley Orgánica de Protección de Datos Personales y garantía de los derechos digitales (LOPDGDD) en España.
El RGPD es la normativa europea que establece un marco uniforme para la protección de datos personales en todos los estados miembros de la Unión Europea. En el caso de las empresas que operan en línea, esta normativa no contempla excepciones, aplazamientos ni periodos de adaptación.
¿Qué implicaciones tiene para una empresa no cumplir con el RGPD?
De manera legal, ninguna compañía podrá ejercer una actividad económica en la Unión Europea si no regula sus operaciones conforme a la normativa europea. En caso de incumplimiento, la empresa puede ser sancionada con una multa de hasta el 4 % de su facturación anual global. En España, esta regulación está respaldada por la Ley Orgánica de Protección de Datos Personales y Garantía de los Derechos Digitales (LOPDGDD) 3/2018.
La LOPDGDD clasifica los tipos de datos en las siguientes categorías:
- Datos de carácter personal: Información relacionada con una persona física identificada o identificable.
- Seudonimización y anonimización: Procesos mediante los cuales los datos personales se tratan de forma que no puedan atribuirse a un interesado sin información adicional específica.
- Categorías especiales de datos: Información sensible que incluye el origen étnico o racial, opiniones políticas, creencias religiosas o filosóficas, afiliación sindical, datos genéticos, biométricos, de salud, vida sexual u orientación sexual de una persona.
En algunos casos, los tratamientos de datos pueden involucrar componentes de inteligencia artificial (IA). Por ejemplo, un modelo publicitario o electoral podría utilizar datos personales de personas físicas. Por otro lado, también existen tratamientos donde no se manejan datos personales, como en un modelo de predicción de la durabilidad de componentes de maquinaria que analiza datos recogidos por sensores distribuidos en una fábrica.
En este contexto, la IA puede tomar decisiones automatizadas que afectan a personas físicas, como el inicio de sesión en un sistema, la firma de un contrato o la asignación de un puesto de trabajo. La inteligencia artificial en la toma de decisiones puede desempeñar dos roles principales:
- Asistir en la toma de decisiones.
- Tomar y ejecutar decisiones de forma autónoma.
La llamada ética digital busca proteger y preservar los valores fundamentales del ser humano frente a las decisiones basadas en razonamientos automatizados. Valores como la dignidad, la libertad, la democracia, la igualdad, la autonomía individual y la justicia son el núcleo de esta preocupación.
El debate ético en la inteligencia artificial es un ámbito de creciente atención, ya que plantea numerosas preguntas. Por ejemplo, consideremos un caso relacionado con la toma de decisiones en la conducción autónoma:
Imaginemos un vehículo autónomo que está a punto de sufrir un accidente. A un lado de la carretera se encuentra una madre con un carrito de bebé, y al otro, un hombre octogenario que intenta cruzar la vía. El vehículo debe tomar una decisión que podría salvar a su tripulación, pero implicaría un sacrificio.
- ¿Debería salvar a la madre con su hijo o al hombre octogenario?
- ¿Debería priorizar la seguridad de la tripulación del vehículo?
- ¿Es posible desarrollar un modelo ético para este tipo de decisiones?
Este tipo de dilemas pone de manifiesto la necesidad de trabajar en el desarrollo de una ética sólida para la inteligencia artificial, que permita guiar su implementación en situaciones críticas y garantizar que los principios humanos sigan siendo el eje central en su diseño y funcionamiento.
Relación de la IA con los sectores productivos
La taxonomía de la inteligencia artificial (IA) es una estructura jerárquica que organiza el conocimiento relacionado con este campo, permitiendo clasificar los diferentes dominios de la IA mediante palabras clave y las relaciones entre ellas.
La inteligencia artificial está cada vez más integrada en la vida diaria de las empresas y los individuos. En los sectores productivos, se desarrollan técnicas avanzadas como el aprendizaje automático (machine learning), el procesamiento de audio y la visión por computadora. Estas tecnologías no solo potencian la automatización de tareas y procesos, sino que también contribuyen a reducir costes y a optimizar la eficiencia operativa.
Además, la IA se está volviendo cada vez más accesible, facilitando su adopción incluso por pequeñas y medianas empresas.
Los principales dominios de la inteligencia artificial incluyen:
- Razonamiento: Capacidad para procesar información y tomar decisiones.
- Planificación: Diseño de estrategias y predicción de resultados.
- Aprendizaje: Adquisición de conocimientos y mejora continua mediante datos.
- Comunicación: Procesamiento y generación de lenguaje natural.
- Percepción: Interpretación de información sensorial, como imágenes y sonidos.
Por otro lado, los dominios secundarios de la inteligencia artificial abarcan:
- Interacción e integración: Conexión entre sistemas y usuarios.
- Ética y filosofía: Reflexión sobre el impacto moral y social de la IA.
- Servicios: Aplicaciones prácticas de la IA en diferentes industrias.
Este enfoque jerárquico permite comprender mejor las capacidades y limitaciones de la inteligencia artificial, así como identificar las áreas de aplicación más relevantes en distintos contextos.
mindmap
root((Taxonomía de la IA))
Core
["`**Razonamiento:** Representación del conocimiento, Razonamiento automatizado, Razonamiento de sentido común`"]
["`**Planificación:** Planificación y programación, Búsqueda, Optimización`"]
["`**Aprendizaje:** Aprendizaje máquina`"]
["`**Comunicación:** Procesamiento natural del lenguaje`"]
["`**Percepción:** Visión por computadora, Procesamiento de audio`"]
Transversal
["`**Integración e interacción**: Sistemas multiagente, Robótica y automatización, Vehículos conectados y automatizados`"]
["`**Ética y filosofía:** Ética IA, Filosofía IA`"]
["`**Servicios:** Servicios IA`"]
Impacto de la automatización y de la IA
Impacto en el mercado laboral
Aunque la automatización y la guía tienen la capacidad de incrementar de forma importante los beneficios, aumentando la productividad, la innovación y la eficiencia. También plantean retos directamente relacionados con la mano de obra y diversos sectores de la economía.
Transformación de la fuerza laboral
La automatización y la inteligencia artificial (IA) están transformando profundamente el mercado laboral, lo que puede generar un desplazamiento significativo en determinados puestos de trabajo. En particular, aquellos empleos que dependen de tareas rutinarias, repetitivas y fácilmente automatizables son los más vulnerables. Por ejemplo, los puestos de trabajo relacionados con la fabricación en cadena, donde las actividades suelen consistir en realizar las mismas acciones una y otra vez, corren un alto riesgo de ser reemplazados por máquinas. Asimismo, áreas como la entrada de datos y otras funciones administrativas rutinarias están siendo progresivamente asumidas por sistemas automatizados.
Sin embargo, a medida que algunas ocupaciones desaparecen o se transforman, también se crean nuevas oportunidades laborales. La introducción de la IA y las tecnologías emergentes impulsa la demanda de perfiles profesionales altamente cualificados en áreas como la programación, el análisis de datos, la ciberseguridad, el desarrollo de algoritmos y la integración de sistemas automatizados. Además, estas tecnologías también generan la necesidad de especialistas que trabajen en la supervisión, mantenimiento y mejora de los sistemas de inteligencia artificial y robótica.
Por otro lado, no solo se trata de empleos técnicos. Los sectores relacionados con la ética de la IA, la interpretación de datos y la comunicación entre sistemas tecnológicos y personas también están ganando relevancia. Estas áreas requieren profesionales con habilidades tanto técnicas como humanas, que puedan garantizar que las tecnologías sean implementadas de manera responsable, equitativa y en beneficio de la sociedad.
En resumen, mientras que algunas ocupaciones tradicionales pueden desaparecer debido al avance de la automatización, también surgen nuevas oportunidades laborales que demandan habilidades específicas. Para adaptarse a este cambio, es fundamental invertir en la formación y el desarrollo de competencias en tecnologías emergentes, fomentando una transición laboral que permita a las personas aprovechar las oportunidades del futuro del trabajo.
Cambio de competencias y formación
La fuerza laboral de las empresas deberá adaptarse a esta nueva realidad tecnológica adquiriendo las habilidades necesarias para operar de manera eficaz con las tecnologías emergentes. Solo así podrán mantener su relevancia y competitividad dentro de las organizaciones.
En este contexto, el aprendizaje permanente y la mejora continua de las cualificaciones se convierten en pilares fundamentales. La capacidad de actualizar conocimientos y adquirir nuevas competencias es esencial para que las personas sigan siendo competitivas en un entorno laboral en constante evolución.
Para lograrlo, es imprescindible una colaboración estrecha entre las instituciones educativas y las empresas. Ambas partes deben trabajar conjuntamente para diseñar programas de formación que estén alineados con las necesidades reales del mercado laboral. Esto implica identificar de manera proactiva las habilidades clave que serán necesarias para prosperar en la era de la automatización y la inteligencia artificial, y proporcionar a las plantillas las herramientas necesarias para desarrollarlas.
De esta manera, se podrá garantizar una transición laboral más eficiente y sostenible, permitiendo que tanto las empresas como los trabajadores se beneficien de las oportunidades que ofrecen las tecnologías emergentes.
Disrupción en los sectores productivos
Es muy posible que algunas industrias experimenten una transformación significativa debido a la automatización y la IA, por ejemplo sectores, como el transporte, la fabricación, el comercio minorista y la agricultura pueden verse abocados a tener que modificar la forma en que ejecutan los procesos y las funciones que desempeña el personal trabajador Con casi toda seguridad, el modelo de negocio tradicional tiene que replantearse a medida que la automatización y la inteligencia artificial, cambien la forma de producir sus productos y servicios.
Creatividad e innovación
La automatización y la inteligencia artificial ofrecen la oportunidad de liberar a la fuerza laboral humana de tareas repetitivas, permitiendo que las personas concentren sus esfuerzos en actividades más creativas e innovadoras. Al enfocar el talento humano en funciones con mayor recorrido y valor añadido, estas tecnologías pueden facilitar grandes avances y convertirse en una ventaja competitiva. Esto no solo impulsa el progreso empresarial, sino que también permite a las personas contribuir de manera significativa, fortaleciendo la dinámica organizacional y fomentando un entorno más enriquecedor.
Consideraciones éticas y sociales
El avance de la automatización y la inteligencia artificial plantea importantes cuestiones éticas y sociales. Entre las principales preocupaciones se encuentran la posible pérdida de empleos, la privacidad de los datos y la concentración de poder en manos de quienes controlan estas tecnologías.
Para abordar estos desafíos, es esencial que los líderes de la industria adopten un enfoque sensible y responsable. Deben escuchar y atender las inquietudes de los empleados y de la sociedad en general, asegurando que los beneficios de la automatización se distribuyan de manera equitativa. Además, es necesario desarrollar estrategias que integren el potencial industrial con la creación de fortalezas laborales, garantizando que este proceso beneficie a toda la fuerza laboral.
Solo a través de una gestión ética y colaborativa será posible maximizar el impacto positivo de la automatización y la inteligencia artificial, generando un entorno más justo, inclusivo y sostenible para todos.
Impacto en la economía
Es innegable que la automatización y la inteligencia artificial tienen el potencial de impulsar significativamente la productividad y fomentar un crecimiento económico notable. Sin embargo, también existe el riesgo de que estas tecnologías agraven la desigualdad laboral si determinados grupos de trabajadores y trabajadoras quedan relegados a tareas menos técnicas y, en consecuencia, con menor remuneración.
Para abordar estos desafíos, las organizaciones y los responsables políticos en materia laboral deben desarrollar estrategias sólidas que gestionen adecuadamente el impacto económico de la automatización. Esto podría incluir la implementación de acuerdos laborales alternativos que permitan reubicar a los trabajadores cuyos puestos podrían ser desplazados, facilitando así su adaptación a nuevos roles con mayor valor añadido.
En conclusión, aunque estas tecnologías son muy prometedoras y promueven el progreso y la modernización de la sociedad, es esencial diseñar políticas bien estructuradas que garanticen una transición gradual. Solo a través de una planificación cuidadosa será posible minimizar las consecuencias negativas y maximizar los beneficios en un mundo laboral en constante transformación.
Ciencia de Datos
La ciencia de datos es una disciplina que se encarga de extraer conocimiento y valor a partir de grandes volúmenes de datos. Utiliza técnicas y herramientas de diversas áreas, como la estadística, el aprendizaje automático y la visualización de datos, para analizar, interpretar y predecir fenómenos a partir de información cuantitativa.
Uno de los procedimientos técnicos más comunes en la ciencia de datos es la minería de datos, que consiste en identificar patrones y relaciones en conjuntos de datos complejos. A través de algoritmos y técnicas de análisis, se pueden descubrir tendencias, correlaciones y anomalías que permiten comprender mejor el comportamiento de los datos y tomar decisiones informadas.
Minería de Datos
Se trata del proceso técnico o el método que se emplea para identificar anomalías patrones y correlaciones en extensos conjuntos de datos con el objetivo de prever resultados mediante el uso de diversas técnicas. Esta información puede ser aprovechada para aumentar ingresos, reducir costes, fortalecer relaciones con los clientes mitigar, riesgos y lograr mejoras significativas en diversos aspectos. La minería de datos se emplea fundamentalmente en tres campos:
- Estadística: estudio numérico de datos y sus relaciones, que se emplea para describir y analizar fenómenos.
- Inteligencia Artificial: disciplina que busca desarrollar sistemas capaces de pensar y actuar de forma autónoma.
- Machine Learning: rama de la inteligencia artificial que se enfoca en el desarrollo de algoritmos y modelos que permiten a las máquinas aprender de los datos y mejorar su rendimiento con el tiempo para realizar predicciones.
graph TD
A[Minería de datos] --> B[Conjuntos de datos]
B --> C
A --> C[Preprocesamiento]
C --> D
A --> D[Clasificación]
D --> E
A --> E[Base de datos]
E --> F
A --> F[Estadísticas]
F --> G
A --> G[Análisis]
G --> H
A --> H[Evaluación]
La minería de datos se divide en dos enfoques principales: predictivo y descriptivo. El primero se basa en modelos estadísticos para realizar pronósticos, mientras que el segundo busca descubrir patrones ocultos en los datos. Los especialistas en esta área tienen formación en diversas disciplinas, como estadística, informática y negocios. Cabe destacar que el término 'minería de datos' también se utiliza en el contexto de la web para describir la extracción de información a través de motores de búsqueda.
Datos: El nuevo petróleo
Los Datos como Recurso Estratégico
Una de las características de la sociedad de la información y el conocimiento es el número creciente de datos generados tanto por individuos como empresas, también conocido como datificación.
 Learn more in DOMO
Learn more in DOMO
Los datos se han convertido en el recurso más valioso de la era digital. Las razonas son varias, destacamos las siguientes:
- Toma de decisiones informada: Los datos permiten a las empresas y organizaciones tomar decisiones basadas en evidencia real en lugar de intuiciones. Esto reduce el riesgo y aumenta la probabilidad de éxito en estrategias de negocio.
- Personalización y mejora de servicios: El análisis de datos de clientes permite a las empresas personalizar sus productos y servicios, mejorando la experiencia del usuario y aumentando la satisfacción y lealtad del cliente.
- Innovación y desarrollo de productos: Los datos sobre el comportamiento del consumidor y las tendencias del mercado impulsan la innovación, permitiendo a las empresas desarrollar nuevos productos y servicios que satisfagan las necesidades emergentes.
- Optimización de procesos: El análisis de datos operativos ayuda a las empresas a identificar ineficiencias y optimizar sus procesos, lo que lleva a una reducción de costos y un aumento de la productividad.
- Predicción de tendencias: Los modelos predictivos basados en datos históricos permiten a las empresas anticipar tendencias futuras del mercado y comportamientos del consumidor, dándoles una ventaja competitiva.
- Creación de nuevos modelos de negocio: Los datos en sí mismos se han convertido en un producto valioso, dando lugar a nuevos modelos de negocio basados en la recopilación, análisis y venta de datos.
- Ventaja competitiva: Las empresas que mejor manejan y aprovechan sus datos tienden a superar a sus competidores en términos de eficiencia, innovación y satisfacción del cliente.
En definitiva, los datos son considerados el "nuevo petróleo" de la economía digital.
Diferencia entre Dato e Información
Antes de adentrarnos en el mundo de los datos, es fundamental establecer una distinción clara entre dato e información.
- Dato: Es una unidad de información sin procesar, un hecho aislado que por sí solo no tiene un significado concreto. Por ejemplo, un número de teléfono o una fecha de nacimiento.
- Información: Es el resultado de procesar, organizar y analizar los datos, otorgándoles un contexto y un significado. Por ejemplo, un análisis de las edades de los clientes de una tienda puede ofrecer información sobre el perfil de los consumidores.
En conclusión, los datos son la materia prima de la información. La ciencia de datos se encarga de transformar esos datos en información valiosa que puede ser utilizada para resolver problemas y tomar decisiones.
Recursos
Tipos de Datos
Según su Naturaleza
Datos Cuantitativos
Los datos cuantitativos son aquellos que se pueden medir y expresar numéricamente. Estos datos se dividen en dos categorías: continuos y discretos.
- Datos Continuos: Son aquellos que pueden tomar cualquier valor dentro de un rango determinado. Por ejemplo, la altura de una persona, la temperatura ambiente o el peso de un objeto.
- Datos Discretos: Son aquellos que solo pueden tomar valores enteros o específicos. Por ejemplo, el número de hijos de una familia, la cantidad de productos vendidos en un mes o el número de estudiantes en una clase.
Datos Cualitativos o Categóricos
Los datos cualitativos o categóricos son aquellos que representan cualidades o atributos que no se pueden medir numéricamente. Estos datos se dividen en dos categorías: nominales y ordinales.
- Datos Nominales: Son aquellos que representan categorías o clases que no tienen un orden específico. Por ejemplo, el color de los ojos, el género de una persona o el tipo de sangre.
- Datos Ordinales: Son aquellos que representan categorías o clases que tienen un orden específico. Por ejemplo, la calificación de un estudiante (sobresaliente, notable, aprobado, suspenso), el nivel de satisfacción de un cliente (muy satisfecho, satisfecho, neutral, insatisfecho, muy insatisfecho) o la posición de llegada en una carrera (primero, segundo, tercero, etc.).
Según su Estructura
Otra forma habitual de clasificar los datos es según su formato o estructura. Bajo esta clasificación nos encontramos con los datos estructurados, semiestructurados y no estructurados.
Datos Estructurados
Los datos estructurados son aquellos que tienen un patrón rígido perfectamente definido y organizado, lo que facilita su almacenamiento y procesamiento. Habitualmente se presentan en forma de tablas, donde cada fila representa una entidad y cada columna un atributo. Además, cada atributo tiene un tipo de dato específico, como texto, número, fecha, etc. Las bases de datos relacionales son un ejemplo de almacenamiento de datos estructurados, ya que permiten definir tablas con esquemas predefinidos y relaciones entre ellas.
Datos No Estructurados
Los datos no estructurados se definen como datos presentes en forma absoluta sin una definición o patrón dado. Estos datos son difíciles de procesar debido a su compleja organización y formato. Los datos no estructurados incluyen publicaciones en redes sociales, chats, imágenes satelitales, datos de sensores de IoT, correos electrónicos, ficheros de audio y video, entre otros.
Datos Semiestructurados
Los datos semiestructurados son una mezcla de datos estructurados y no estructurados. Aunque tienen un formato definido, no siguen un esquema rígido como los datos estructurados. Los datos semiestructurados son comunes en la web, donde se utilizan formatos como XML, JSON o YAML para almacenar información con cierta organización, pero sin una estructura fija.
Recursos
- VIDEO: 3 - Datos cuantitativos y datos cualitativos
- VIDEO: 4 - Datos continuos y datos discretos
- VIDEO: 5 - Datos nominales y datos ordinales
- VIDEO: 6 - Datos estructurados y no estructurados
Ciclo de Vida del Dato
El ciclo de vida del dato es un proceso que describe las etapas por las que atraviesa un dato desde su creación hasta su eliminación. Estas etapas nos ayudan a comprender cómo se generan, utilizan y finalmente eliminan o reutilizan los datos. Cada fase aporta valor y requiere una gestión adecuada para garantizar la calidad, seguridad y utilidad de la información.
Etapas del Ciclo de Vida del Dato
El ciclo de vida del dato se compone de las siguientes etapas:
- Creación: En esta fase, los datos llegan a una organización. Los datos pueden generarse a partir de diversas fuentes, como transacciones comerciales, sensores, interacciones con usuarios, registros de sistemas, etc.
- Captura: Los datos se recopilan y almacenan en un repositorio centralizado. Es fundamental garantizar la integridad y la calidad de los datos durante este proceso. Los datos provenientes de distintas fuentes se unifican para crear un conjunto de datos coherente. Durante esta fase, se identifican, etiquetan y registran los datos relevantes.
- Preparación: Los datos se limpian, transforman y enriquecen para su posterior análisis. En esta etapa, se eliminan duplicados, se corrigen errores, se normalizan formatos y se enriquecen los datos con información adicional. El objetivo es garantizar que los datos sean coherentes, precisos y completos.
- Análisis: Los datos se procesan y se analizan para extraer información valiosa. Durante esta fase, se aplican técnicas de minería de datos, aprendizaje automático y análisis estadístico para identificar patrones, tendencias y relaciones ocultas en los datos.
- Almacenamiento: Los datos se almacenan en un repositorio seguro y accesible. Es fundamental garantizar la integridad, la disponibilidad y la confidencialidad de los datos almacenados. Las bases de datos, los sistemas de almacenamiento en la nube y los data lakes son ejemplos de infraestructuras de almacenamiento utilizadas en esta etapa.
- Visualización: Los resultados del análisis se presentan de forma clara y comprensible. Las visualizaciones, los informes y los cuadros de mando permiten a los usuarios interpretar los datos de manera efectiva y tomar decisiones informadas. El objetivo es comunicar los hallazgos de manera visual y accesible para facilitar la comprensión de los mismos.
- Distribución: Los resultados del análisis se comparten con los usuarios finales o las partes interesadas. Es fundamental garantizar que los datos se distribuyan de forma segura y que solo las personas autorizadas tengan acceso a la información. Las herramientas de colaboración, los portales de datos y los sistemas de gestión de contenidos son ejemplos de plataformas utilizadas para la distribución de datos.
- Archivado: Los datos se archivan de forma segura y se conservan durante un período determinado. Los datos se eliminan de forma segura cuando ya no son necesarios. Es fundamental establecer políticas de retención de datos para garantizar el cumplimiento de las regulaciones, requisitos legales y la disponibilidad de la información en el futuro. Los sistemas de gestión de archivos y las soluciones de almacenamiento a largo plazo son utilizados en esta etapa.
En resumen, el ciclo de vida de los datos permite una gestión eficiente y segura de la información, desde su origen hasta su destino final.
Ejemplo de Ciclo de Vida del Dato
Imagina una tienda en línea. Los datos de las compras de los clientes se generan en cada transacción (creación). Estos datos se almacenan en una base de datos (captura). Luego, se limpian y se analizan para identificar patrones de compra (procesamiento y análisis). Con esta información, se pueden crear campañas de marketing personalizadas y mejorar la experiencia del cliente (distribución). Finalmente, los datos históricos se archivan para realizar análisis a largo plazo (archivado).
Fuentes de Datos
Las fuentes de datos son los lugares o sistemas de donde se obtienen los datos que se van a analizar. Estas fuentes pueden ser internas o externas a la organización y pueden ser de diferentes tipos, como bases de datos, archivos, sensores, redes sociales, entre otros.
Precisamente, la variedad (una de las 5 V's del big data) de fuentes de datos es uno de los principales desafíos del Big Data, ya que requiere técnicas avanzadas de procesamiento y análisis para extraer información valiosa y relevante.
Entre las fuentes de datos habituales se destacan:
- Bases de datos
- IoT
- CMS
- ERP
- CRM
- APIs
- Redes sociales
Entre otros.
Recursos
Disciplinas del dato
En el ecosistema de las disciplinas del dato, la interacción entre Big Data, análisis de datos, machine/deep learning e inteligencia artificial (IA) es esencial para que las empresas puedan transformar la vasta cantidad de información que generan en insights accionables y valor tangible. Cada una de estas disciplinas desempeña un papel clave en el proceso de convertir datos en decisiones inteligentes. La Ciencia de Datos actúa como un paraguas que integra las disciplinas mencionadas anteriormente junto con la matemática, estadística y programación. Al aplicar conocimientos del dominio específico, permite extraer información valiosa a partir de los datos.
- Big Data: (La base de la materia prima)
Big Data se refiere a los grandes volúmenes de datos, tanto estructurados como no estructurados, que se recopilan de diversas fuentes, como transacciones comerciales, redes sociales, sensores o imágenes satelitales. Estos datos en bruto representan la materia prima que alimenta todo el proceso de análisis y aprendizaje. Sin Big Data, no habría suficiente información para extraer patrones o insights significativos.
- Análisis de datos: (Transformación de datos en conocimiento)
El análisis de datos es el proceso de limpieza, transformación y organización de los datos para extraer información útil. Mediante técnicas estadísticas y matemáticas, se identifican patrones, tendencias y correlaciones que permiten comprender el comportamiento subyacente en los datos. Esta etapa es crucial para preparar los datos y garantizar que estén listos para ser utilizados en modelos de machine learning o deep learning.
- Machine learning y deep learning: (Aprendizaje automático para descubrir patrones complejos)
Estas técnicas permiten a los sistemas aprender automáticamente de los datos y realizar tareas específicas sin ser programados explícitamente. Mientras que el machine learning se enfoca en algoritmos que identifican patrones y hacen predicciones, el deep learning utiliza redes neuronales para analizar datos más complejos, como imágenes o texto. Estas herramientas son fundamentales para tareas como la clasificación, predicción y detección de anomalías.
- Inteligencia artificial: (La culminación de la automatización inteligente)
La IA integra todas estas disciplinas para crear sistemas capaces de realizar tareas que normalmente requerirían inteligencia humana. Utiliza los datos procesados, los modelos entrenados y los algoritmos de aprendizaje para tomar decisiones autónomas, razonar y mejorar continuamente su desempeño. La IA no solo automatiza procesos, sino que también los optimiza y adapta en tiempo real.
Ejemplo práctico: Sistema de recomendación en comercio electrónico
Imaginemos una empresa de comercio electrónico que busca mejorar la experiencia de sus clientes mediante recomendaciones personalizadas:
- Big Data: Recolecta datos de compras, búsquedas e interacciones de los usuarios en su plataforma.
- Análisis de datos: Analiza estos datos para identificar patrones de compra, productos frecuentemente adquiridos juntos y preferencias individuales.
- Machine/deep learning: Entrena un modelo de recomendación que, basado en datos históricos, sugiere productos personalizados para cada cliente.
- Inteligencia artificial: Implementa un sistema inteligente que mejora continuamente sus recomendaciones a medida que recibe más datos, ofreciendo una experiencia cada vez más adaptada a las necesidades del cliente.
En conjunto, estas disciplinas del dato permiten a las empresas no solo comprender el presente, sino también anticipar el futuro, optimizar operaciones y ofrecer soluciones innovadoras basadas en datos.
Ciberseguridad
La seguridad es el proceso continuado de proteger un objeto contra un acceso no autorizado. Este concepto abarca una amplia gama de ámbitos y se aplica a diversos tipos de objetos, todos los cuales requieren medidas adecuadas de protección. Aquí debemos entender que un objeto puede ser una persona, una organización, un negocio, un servicio web o una propiedad física como un equipo informático o un dispositivo móvil, por citar algunos ejemplos. Incluso, la información contenida en un simple fichero también se considera un objeto que necesita ser protegido.
La protección de estos objetos implica la implementación de diversas estrategias y tecnologías diseñadas para prevenir el acceso no autorizado, el robo, la alteración o la destrucción de datos. Esto incluye el uso de contraseñas seguras, encriptación, firewalls, software antivirus y otras herramientas de seguridad.
Cuando hablamos de ciberseguridad o seguridad de las tecnologías de la información y la comunicación (TIC), los objetos que deben protegerse son específicamente sistemas informáticos, redes, programas y datos. En este contexto, la ciberseguridad se enfoca en proteger estos componentes contra ciberataques, que pueden incluir virus, malware, ataques de phishing, ransomware, y otros métodos que los cibercriminales utilizan para comprometer la seguridad de la información.
Es fundamental reconocer que la ciberseguridad no solo se refiere a la protección de datos contra amenazas externas, sino también contra amenazas internas, como empleados que puedan tener intenciones maliciosas o que accidentalmente comprometan la seguridad de los sistemas. Además, la ciberseguridad abarca políticas y procedimientos que ayudan a asegurar que los sistemas de información y las redes sean utilizados de manera segura y responsable.
Un aspecto crucial de la seguridad, tanto física como cibernética, es la evaluación continua de riesgos y la implementación de planes de contingencia. Esto incluye la identificación de vulnerabilidades, la evaluación de las posibles amenazas y la preparación para incidentes de seguridad, asegurando así una respuesta rápida y efectiva para minimizar el impacto de cualquier violación de seguridad.
Relevancia
Mapa de ataques en tiempo real - Kaspersky
En los últimos años, la ciberseguridad ha cobrado una relevancia significativa debido a la creciente incidencia de incidentes y amenazas en el entorno digital. Este aumento en la preocupación por la ciberseguridad no es infundado, ya que se ha observado un incremento notable en el número de ciberataques a nivel global. Estas agresiones no distinguen entre el sector público y privado, afectando tanto a empresas como a instituciones gubernamentales y no gubernamentales. El impacto de estos ataques puede ser devastador, resultando en pérdidas financieras, compromisos de datos sensibles y daños a la reputación de las organizaciones.
Uno de los principales focos de preocupación en el ámbito de la ciberseguridad es la vulnerabilidad de las pequeñas y medianas empresas (PYMES). Estas entidades se han convertido en eslabones más débiles dentro de la cadena de seguridad cibernética debido a varios factores. En primer lugar, las PYMES suelen contar con recursos limitados, lo que les impide invertir en medidas de protección avanzadas que podrían mitigar los riesgos cibernéticos. A diferencia de las grandes corporaciones, que pueden destinar presupuestos significativos para la implementación de tecnologías de seguridad sofisticadas y para la contratación de personal especializado, las PYMES deben gestionar sus limitados recursos con mayor restricción.
Además, las PYMES son frecuentemente objetivos de ciberdelincuentes debido a sus sistemas menos protegidos. Los atacantes ven a estas empresas como blancos más fáciles, ya que, por lo general, no cuentan con la misma robustez en sus defensas cibernéticas en comparación con las grandes empresas. Este hecho se agrava porque muchas PYMES actúan como subcontratistas para corporaciones más grandes. Al comprometer la seguridad de una pequeña empresa que forma parte de la cadena de suministro de una entidad más grande, los atacantes pueden acceder a información sensible o a sistemas críticos de estas grandes empresas a través de los eslabones más débiles.
La situación descrita subraya la necesidad urgente de abordar la ciberseguridad de manera integral, considerando no solo a las grandes corporaciones, sino también a las pequeñas y medianas empresas que, aunque menos protegidas, son vitales para la economía y la seguridad general de la cadena de suministro. Las estrategias de ciberseguridad deben incluir medidas específicas para fortalecer las defensas de las PYMES, como programas de capacitación, subsidios para la implementación de tecnologías de seguridad y el fomento de una cultura de ciberseguridad que permee en todos los niveles de la organización.
La relevancia reciente de la ciberseguridad, potenciada por el aumento en la frecuencia y sofisticación de los ciberataques, exige una respuesta coordinada y bien planificada que involucre tanto a actores públicos como privados. Solo mediante un esfuerzo conjunto se podrá reducir la vulnerabilidad general del ecosistema digital, protegiendo así a todas las entidades que forman parte de él, desde las más pequeñas hasta las más grandes.
Seguridad Informática vs. Seguridad de la Información
En el mundo digital, proteger datos y sistemas es esencial. Sin embargo, los términos seguridad informática y seguridad de la información suelen confundirse. Aunque están relacionados, tienen diferencias clave que es importante comprender.
Seguridad Informática
Definición: Se enfoca en proteger los medios tecnológicos donde la información se crea, almacena, gestiona o destruye.
Características:
- Es de naturaleza técnica.
- Cubre herramientas y métodos para salvaguardar sistemas, redes y datos.
Ejemplos Prácticos:
- Criptografía: Técnicas para cifrar datos y garantizar su confidencialidad.
- Seguridad en redes: Firewalls, sistemas de detección de intrusos, etc.
- Protección de software: Métodos para evitar vulnerabilidades en aplicaciones y bases de datos.
¿Quién la gestiona? El Director de Seguridad Informática, un perfil técnico especializado en tecnología y redes.
Seguridad de la Información
Definición: Aborda la protección de la información desde una perspectiva integral, incluyendo aspectos técnicos, organizativos y legales.
Características:
- Es estratégica y sistémica.
- Considera políticas, normativas y riesgos empresariales.
Ejemplos Prácticos:
- Gestión del riesgo: Evaluar amenazas y diseñar planes de mitigación.
- Políticas de seguridad: Establecer normas para el buen gobierno corporativo.
- Cumplimiento legal: Adecuarse a regulaciones como GDPR (protección de datos) o ISO 27001.
¿Quién la gestiona? El Director de Seguridad de la Información, un perfil estratégico que alinea la seguridad con los objetivos de la empresa.
Diferencias Clave
| Aspecto | Seguridad Informática | Seguridad de la Información |
|---|---|---|
| Enfoque | Tecnológico (herramientas) | Estratégico (gestión global) |
| Ámbito | Sistemas, redes, software | Empresa, normativas, riesgos |
| Responsable | Director de Seguridad Informática | Director de Seguridad de la Información |
Relación: Ambos enfoques son complementarios pues se concibe la seguridad informática como una parte de la seguridad de la información.
Conclusión
- Seguridad informática = Tecnología.
- Seguridad de la información = Tecnología + Estrategia + Legal.
Areas principales
Las principales áreas que cubre la ciberseguridad son fundamentales para proteger la integridad, confidencialidad y disponibilidad de la información en el entorno digital. Entre estas áreas, se encuentran:
- Seguridad de la información Esta área se enfoca en proteger la información contra accesos no autorizados, modificaciones indebidas y destrucción. Incluye la implementación de políticas de seguridad, control de acceso y medidas de protección de datos.
- Seguridad en redes: La seguridad en redes se ocupa de proteger las redes de comunicación contra ataques y accesos no autorizados. Esto implica el uso de firewalls, sistemas de detección y prevención de intrusiones, y el cifrado de datos transmitidos.
- Seguridad de las aplicaciones: Esta área se concentra en garantizar que las aplicaciones sean seguras desde el desarrollo hasta su implementación y mantenimiento. Incluye la revisión de código, pruebas de penetración y la implementación de prácticas de desarrollo seguro.
- Seguridad operativa: La seguridad operativa abarca la protección de los procesos y procedimientos utilizados para gestionar y operar los sistemas de información. Incluye la gestión de incidentes, la respuesta ante emergencias y la implementación de controles operacionales.
- Gestión de riesgos y continuidad de negocio: Esta área se encarga de identificar, evaluar y mitigar los riesgos de ciberseguridad. Además, se enfoca en desarrollar planes de continuidad de negocio para asegurar que las operaciones puedan continuar en caso de un incidente de seguridad.
Además de estas áreas, es crucial subrayar la importancia de la educación en buenas prácticas de seguridad para los usuarios finales. La capacitación y concienciación de los usuarios sobre los riesgos y las medidas de seguridad son vitales, ya que actualmente se estima que el 95% de las incidencias de ciberseguridad se deben a errores humanos. Esto incluye el uso adecuado de contraseñas, la identificación de correos electrónicos de phishing, y la adopción de hábitos seguros en el uso de dispositivos y redes.
Seguridad de la información y gestión de riesgos
Esta sección aborda los principios fundamentales de la seguridad de la información y la gestión de riesgos, pilares esenciales para la protección de los activos digitales organizacionales. El punto de partida para su comprensión es la definición del concepto central: riesgo.
Definición de Riesgo
En seguridad de la información, el riesgo se define como la materialización de vulnerabilidades identificadas —debilidades susceptibles de ser explotadas por amenazas internas o externas—. Su evaluación integral considera:
- La probabilidad de ocurrencia de eventos adversos.
- Las amenazas potenciales.
- El impacto operacional y empresarial.
Una gestión efectiva requiere: identificación proactiva de vulnerabilidades, análisis de probabilidades, comprensión del panorama de amenazas e implementación de controles para mitigar consecuencias.
Propiedades de la Seguridad
La seguridad de la información se sustenta en seis propiedades interrelacionadas que garantizan la protección y operatividad de sistemas y datos:
-
Disponibilidad
- Definición: Capacidad de mantener sistemas, servicios y datos accesibles para usuarios autorizados cuando sean requeridos.
- Implementación: Estrategias de redundancia, planes de recuperación ante desastres (DRP) y monitoreo continuo para minimizar tiempos de inactividad.
-
Comunicación segura
- Definición: Intercambio eficaz y protegido de información entre sistemas, dispositivos y personal.
- Relevancia: Facilita la coordinación ante incidentes, el intercambio de inteligencia sobre amenazas y la concienciación organizacional. Requiere protocolos cifrados para prevenir interceptaciones.
-
Identificación de problemas
- Definición: Detección temprana de vulnerabilidades, fallos o comportamientos anómalos mediante herramientas de monitoreo y análisis.
- Impacto: Permite respuestas rápidas, reduciendo el alcance de incidentes y optimizando medidas correctivas.
-
Análisis de riesgos
- Proceso: Identificación sistemática, evaluación cuantitativa/cualitativa y priorización de riesgos.
- Objetivo: Fundamentar decisiones estratégicas y asignar recursos eficientemente para la mitigación.
-
Integridad
- Definición: Garantía de que los datos mantienen su exactitud y consistencia, sin modificaciones no autorizadas.
- Mecanismos: Controles de acceso, firmas digitales, checksums y cifrado en tránsito/reposo.
-
Confidencialidad
- Definición: Protección de información sensible contra accesos o divulgaciones no autorizadas.
- Herramientas: Políticas de acceso mínimo privilegiado, encriptación y cumplimiento de normativas (GDPR, ISO 27001).
Conclusión
La convergencia de estas propiedades —disponibilidad, comunicación, identificación proactiva, análisis de riesgos, integridad y confidencialidad— constituye el marco de una estrategia de seguridad holística. Su implementación coordinada fortalece la resiliencia organizacional frente a amenazas evolutivas, asegurando la continuidad operativa y la protección del activo más crítico: la información.
La tríada CIA
En muchas ocasiones, vamos a ver que se habla de la tríada CIA, por sus siglas en inglés: Confidentiality, Integrity, Availability), que representa la Confidencialidad, Integridad y Accesibilidad (disponibilidad), es un modelo fundamental diseñado para guiar las políticas de seguridad de la información dentro de una organización. Estos tres componentes se consideran los pilares más cruciales de la seguridad.
-
La confidencialidad (confidentiality) es un principio fundamental que garantiza que la información sensible solo pueda ser accedida por personas o sistemas autorizados, evitando así su exposición a entidades no autorizadas. Su principal objetivo es prevenir fugas de datos, proteger información crítica como datos personales o secretos comerciales, y cumplir con regulaciones estrictas como el GDPR, HIPAA o ISO 27001. Para implementar este principio, se emplean medidas como el cifrado de datos tanto en tránsito como en reposo, controles de acceso rigurosos que incluyen autenticación multifactor y el principio de mínimo privilegio, así como políticas de clasificación de datos que permiten etiquetar y manejar adecuadamente la información confidencial.
-
La integridad (integrity) asegura que los datos no sean alterados, eliminados o corrompidos de manera no autorizada, manteniendo su exactitud y consistencia a lo largo de su ciclo de vida. Este aspecto busca evitar modificaciones malintencionadas o accidentales, garantizando que la información sea confiable para la toma de decisiones. Entre las medidas clave para preservar la integridad se encuentran el uso de firmas digitales y hashes para verificar la autenticidad de los datos, registros de auditoría (logs) que permiten rastrear cambios, y mecanismos de control de versiones como backups o sistemas WORM (Write Once, Read Many).
-
La disponibilidad (availability) garantiza que los sistemas y datos estén accesibles cuando sean requeridos por usuarios o procesos autorizados, minimizando los tiempos de inactividad. Su propósito es prevenir interrupciones causadas por ataques como DDoS o ransomware, así como por fallos técnicos, asegurando la continuidad del negocio. Para lograrlo, se implementan estrategias como la redundancia mediante servidores en clúster y balanceo de carga, planes de recuperación ante desastres (DRP) y un monitoreo proactivo que permite detectar y resolver incidentes de manera rápida y eficiente.
En conjunto, estos tres pilares —confidencialidad, integridad y disponibilidad— forman la base de la seguridad de la información, protegiendo los activos digitales y asegurando su correcto funcionamiento en todo momento.
Otras propiedades de ciberseguridad
Otras propiedades de la seguridad de la información, que no siempre se requieren, son las siguientes:
-
Autenticación: se dice que un objeto es auténtico cuando es verdadero o hay un certificado que es verdadero o seguro. La autenticación de los usuarios o extremos en una comunicación es una propiedad de seguridad fundamental. Para conseguirla, los servicios o sistemas habilitan mecanismos para que los usuarios presenten sus identidades y las validen. Estos mecanismos pueden incluir contraseñas, tarjetas inteligentes, biometría, entre otros. La autenticación asegura que solo las personas autorizadas puedan acceder a la información o sistemas, protegiendo así la integridad y la confidencialidad de los datos.
-
Anonimato: se puede interpretar como las acciones destinadas a garantizar que el acceso a la red o a un servicio se hace de forma que no se conozca quién ha llevado a cabo la conexión y sus acciones posteriores. El anonimato es crucial en situaciones donde la privacidad del usuario es primordial, como en la navegación web anónima, las comunicaciones seguras y el intercambio de información confidencial. Las tecnologías que facilitan el anonimato, como las redes Tor, los proxys y las VPN, juegan un papel importante en la protección de la identidad y la actividad de los usuarios en línea.
-
No repudio: es la propiedad que garantiza que el autor de una acción determinada no pueda negar que la ha llevado a cabo. El no repudio puede ser tanto de origen como de destino. El no repudio de origen asegura que el remitente de un mensaje o transacción no puede negar haberlo enviado, mientras que el no repudio de destino asegura que el receptor no puede negar haber recibido el mensaje o la transacción. Esta propiedad es esencial en transacciones comerciales y legales, ya que proporciona una prueba irrefutable de la participación de las partes involucradas.
-
Trazabilidad: es la propiedad que asegura que en todo momento se puede determinar quién ha hecho qué y cuándo. Es esencial para analizar los incidentes, perseguir a los atacantes y aprender de la experiencia de los ataques. La trazabilidad permite reconstruir los eventos que ocurrieron en un sistema, lo cual es vital para la auditoría, el cumplimiento normativo y la mejora continua de la seguridad. Herramientas como los registros de auditoría, los sistemas de gestión de eventos de seguridad y las soluciones de monitoreo en tiempo real son fundamentales para mantener la trazabilidad en los sistemas de información.
Estas propiedades, aunque no siempre requeridas en todos los contextos, son componentes importantes de un sistema de seguridad integral. Aportan capas adicionales de protección y aseguran que las operaciones dentro de los sistemas de información sean confiables, verificables y seguras. Cada una de estas propiedades puede ser implementada y gestionada de diferentes maneras según las necesidades específicas de la organización y el tipo de información que se maneje.
Criptografía
Desde los mensajes cifrados de Julio César hasta las transacciones bancarias de hoy, la criptografía ha sido durante siglos el guardián invisible de la información. En esencia, es la ciencia de ocultar y proteger datos, transformándolos en códigos que solo los destinatarios legítimos pueden descifrar.
¿Qué es la Criptografía?
La criptografía es aquella ciencia que hace uso de métodos y herramientas matemáticas con el objetivo principal de cifrar,y por tanto proteger, un mensaje o archivo por medio de un algoritmo, usando para ello dos o más claves, con lo que se logra en algunos casos la confidencialidad, en otros la autenticidad, o bien ambas simultáneamente.
¿Desde cuando existe la criptografía?
Desde el siglo V a. C., el ser humano ha desarrollado técnicas criptográficas para proteger información. Los espartanos utilizaban la escítala, un bastón alrededor del cual se enrollaba una cinta para escribir mensajes cifrados por transposición, que solo podían leerse correctamente con un bastón del mismo diámetro. Con el tiempo, surgieron métodos más avanzados, como la sustitución de caracteres, el cifrado César y sistemas que empleaban múltiples alfabetos.
Durante siglos, se perfeccionaron los criptosistemas, hasta llegar a las máquinas de cifrado del siglo XX, como Enigma y Purple. Sin embargo, un cambio decisivo ocurrió en la segunda mitad del siglo XX. En 1948, Claude Shannon estableció las bases científicas de la criptografía con su teoría de la información. Esto, junto con el desarrollo de la computación y la invención de la criptografía de clave pública por Diffie y Hellman en 1976, marcó el inicio de la criptografía moderna.
A diferencia de la criptografía clásica, centrada en métodos simples y aplicaciones militares, la moderna utiliza herramientas más avanzadas para garantizar confidencialidad, autenticidad e integridad en un mundo digital y se aplica ampliamente en contextos civiles.
Términos empleados en la Criptografía
-
Texto en claro/crudo: Cualquier información que resulta legible y comprensible por sí misma.
-
Criptograma: Texto que resulta de la cifra de cualquier información que no es legible ni comprensible salvo por el destinatario legítimo de la misma.
-
Cifrar y descifrar: Procesos que permiten transformar un texto en claro en un criptograma y viceversa.
-
Esteganografía: Disciplina de la criptografía en la que se estudian técnicas que permiten el ocultamiento de mensajes objetos, de modo que no se perciba su existencia.
-
Criptoanálisis: Estudio de los métodos que permiten romper los procedimientos de cifrado para recuperar la información original o la clave.
-
Criptología: ciencia que estudia la criptografía y el criptoanálisis.
-
Criptógrafo o criptólogo: persona que se dedica al estudio de la criptología.
-
Codificar: Acción estática de asignar valores fijos a elementos (ej: letra A en ASCII siempre es el decimal 65 o binario 0100 0001).
-
Clave (en cifrado): Elemento variable que determina cómo se transforma un mensaje, recomendándose claves únicas y temporales.
Principios de Kerchoffs
Auguste Kerckhoffs (1835-1903) fue un criptógrafo y lingüista neerlandés, pionero en establecer bases científicas para la criptografía. Profesor en París, publicó ensayos seminales en la Revista de Ciencias Militares donde formuló sus principios. Destacó que los sistemas deben ser seguros incluso si el enemigo conoce su diseño, idea que Claude Shannon luego llamó "el adversario conoce el sistema".
Los principios son los siguientes:
-
Seguridad práctica: El sistema debe ser indescifrable en la práctica, en caso de que no lo sea matemáticamente.
-
Clave como único secreto: El sistema no debe ser secreto y no debe ser un problema que éste caiga en manos del enemigo.
-
Clave memorizable: Fácil de memorizar y comunicar a otros sin necesidad de tener que escribirla; será cambiable y modificable por los interlocutores válidos.
-
Resultados alfanuméricos: Los criptogramas deben expresarse en formato legible (letras y números).
-
Operabilidad individual: El sistema debe ser portable y usable eficientemente por una sola persona.
-
Facilidad de uso: El proceso debe ser sencillo, sin requerir conocimientos avanzados.
De entre todos los principios el segundo destaca notablemente como gran aportación. Hoy en día se ha simplificado su enunciado afirmando que la seguridad del sistema debe depender exclusivamente de la clave, no consiste en ocultar el sistema.
Alan Turing y su relación con la criptografía
Difusión y Confusión
Criptografía clásica
Clasificación
La clasificación principal de los sistemas de cifra clásica atiende al tipo de operación que se realizará al texto en claro durante la cifra, bien sea la de transposición con el fin de lograr la difusión, o la de sustitución para lograr en este caso la confusión.
-
Transposición o Permutación: Reorganizan las posiciones de las unidades de texto (letras, pares, grupos, series, columnas o filas) según un esquema geométrico o clave. No modifican los caracteres originales, solo su orden.
-
Algoritmos por sustitución: Reemplazan elementos del texto claro (letras, grupos) por otros según reglas predefinidas. Se dividen en las categorías de sustitución monoalfabética (Cifrado César, Cifrado Afín o Matrices de Hill) o polialfabética (Máquina de Enigma, Vigenère, Vernam).
- Sustitución monoalfabética monográmica: Sustitución letra por letra (ej: cifrado César, donde A → D, B → E, etc.)
- Sustitución monoalfabética poligrámica: Sustitución de grupos de letras (ej: cifrado Playfair, que opera con digramas).
- Sustitución polialfabética periódica: La clave se repite cíclicamente (ej: Vigenère, que usa una palabra clave para seleccionar alfabetos desplazados)
- Sustitución polialfabética no periódica: La clave es única y tan larga como el mensaje. (ej: Vernam, basado en operaciones XOR con una clave aleatoria)
Diffie-Hellman (intercambio de claves)
Principales amenazas
Los ataques cibernéticos son una amenaza constante para las organizaciones de todo el mundo.
Entre los ataques más comunes se encuentra el phishing, una técnica en la que los atacantes engañan a los empleados para que revelen sus credenciales de acceso. Esto se logra a través de correos electrónicos fraudulentos que parecen ser de fuentes legítimas, llevando a los empleados a hacer clic en enlaces maliciosos o proporcionar información confidencial en formularios falsos. El phishing es particularmente peligroso porque puede abrir la puerta a otros tipos de ataques, permitiendo a los ciberdelincuentes acceder a redes internas y sistemas críticos. En este enlace puedes acceder a un test de google para comprobar si serías capaz de detectar cuando te están engañando mediante técnicas de phising.
Otro ataque común es el ransomware. En este tipo de ataque, los atacantes logran introducirse en los sistemas de una organización y cifran archivos importantes, bloqueando el acceso a los mismos. A continuación, exigen el pago de un rescate, generalmente en criptomonedas, para proporcionar la clave de descifrado. El ransomware puede paralizar completamente las operaciones de una organización, causando pérdidas significativas tanto financieras como de reputación. Las víctimas a menudo se enfrentan a la difícil decisión de pagar el rescate, con la esperanza de recuperar sus datos, o intentar restaurar los sistemas por otros medios, lo cual puede ser costoso y llevar mucho tiempo.
En este vídeo, vemos un caso práctico de un ataque de Ramsonware a un gabinete de psicólogos.
La inteligencia artificial (IA) juega un papel dual en el ámbito de la ciberseguridad. Por un lado, se utiliza para mejorar las defensas contra los ataques. Los sistemas basados en IA pueden analizar grandes cantidades de datos en tiempo real, identificando patrones y comportamientos anómalos que podrían indicar un ataque inminente. Estos sistemas pueden aprender y adaptarse continuamente, mejorando su capacidad para detectar amenazas nuevas y emergentes. La IA también puede automatizar respuestas a incidentes, acelerando la contención y mitigación de los mismos, lo cual es crucial para limitar el daño causado por un ataque.
Por otro lado, la inteligencia artificial también puede ser utilizada para desarrollar ataques más sofisticados. Los ciberdelincuentes pueden emplear IA para diseñar malware que evade las medidas de seguridad tradicionales, adaptándose a diferentes entornos y evitando la detección. La IA puede analizar redes y sistemas para identificar vulnerabilidades específicas, permitiendo a los atacantes personalizar sus estrategias de ataque. Además, la IA puede ser utilizada para realizar ataques a gran escala, como campañas de phishing automatizadas, que envían correos electrónicos maliciosos a miles de objetivos en un corto período de tiempo.
Existen muchos otros tipos de ataques cibernéticos, como los ataques de denegación de servicio (DDoS), Spyware, Cryptojacking, Ingeniería social, etc. En concreto, vamos a leer un artículo ofrecido por CheckPoint, sobre los principales tipos de amenazas en ciberseguridad.
A continuación puedes ver un vídeo breve del Instituto Nacional de Ciberseguridad (INCIBE), explicando cómo trabajan los ciberdelincuentes.
El Instituto Nacional de Ciberseguridad
Ciberseguridad en Canarias
Big Data
Las 5 V's del Big Data
Volumen
Cantidad de datos generados y almacenados. El volumen de datos ha crecido exponencialmente en los últimos años debido a la proliferación de dispositivos conectados, las redes sociales, los sensores y otras fuentes de información digital. El manejo eficiente de grandes volúmenes de datos es uno de los principales desafíos del Big Data.
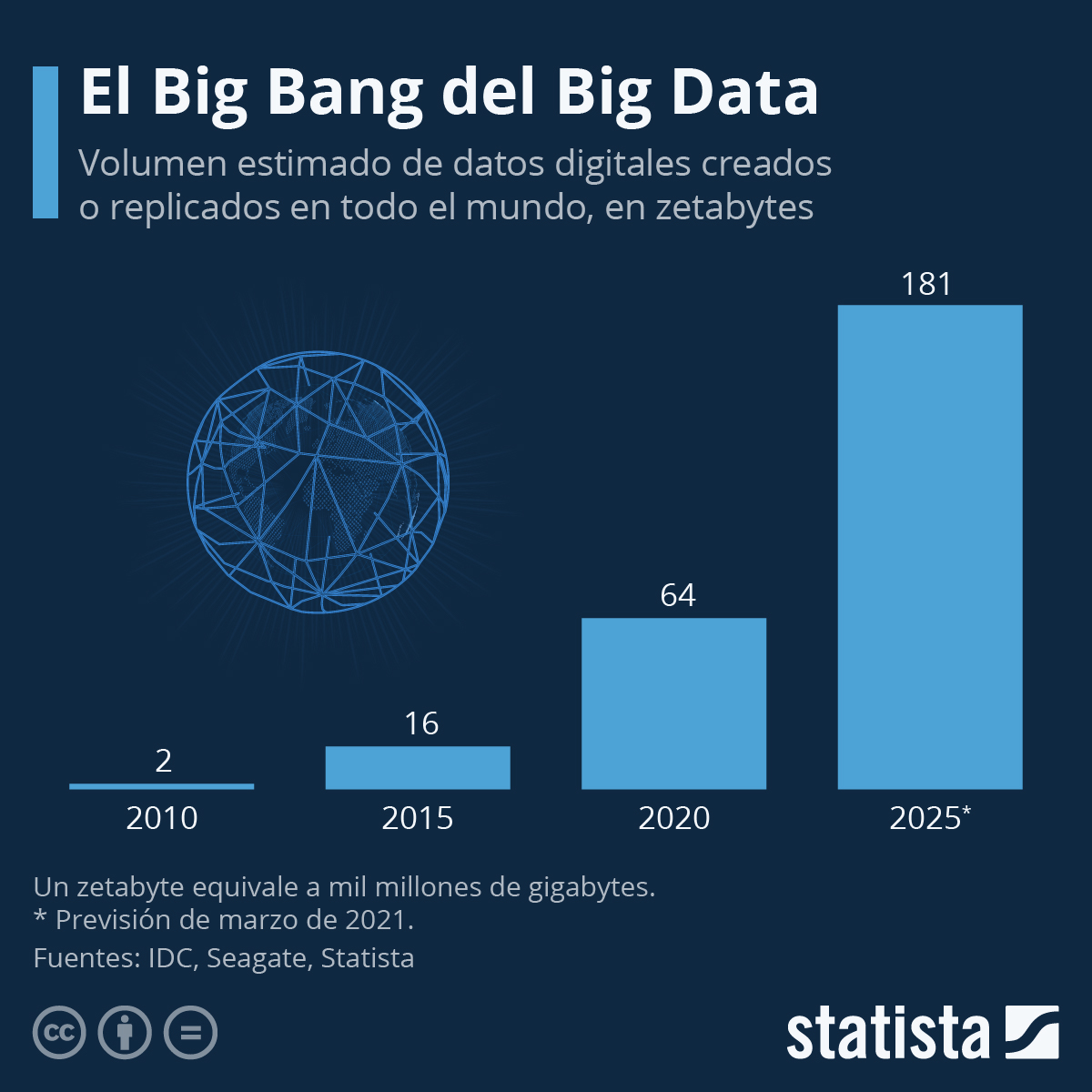 Más infografías en Statista
Más infografías en Statista
Velocidad
Se refiere a la rapidez con la que se generan y se procesan los datos. Los datos se generan a una velocidad realmente alta, a menudo en tiempo real, por ejemplo datos de sensores y transacciones en línea.
Variedad
Nos pueden llegar datos de diferentes fuentes y formatos, algunos estructurados provenientes de BBDD relacionales (MariaDB, MySQL, PostgreSQL), otros semiestructurados (XML, JSON) o no estructurados (texto, imágenes, audio, video, redes sociales, sensores, etc). La variedad de datos requiere técnicas avanzadas de procesamiento y análisis para extraer información valiosa y relevante.
Veracidad
La veracidad se refiere a la calidad, la precisión, la integridad y la confiabilidad de los datos, datos contrastables y útiles. Es fundamental garantizar que los datos sean precisos, completos y actualizados para evitar errores y sesgos en el análisis. Por ello, muchas veces es necesario realizar una limpieza para eliminar errores, inconsistencias y/o valores atípicos.
Valor
El valor es el objetivo final del Big Data. El valor se obtiene al transformar los datos en información valiosa que puede ser utilizada para tomar decisiones informadas, identificar oportunidades de negocio, mejorar la eficiencia operativa y ofrecer servicios personalizados a los clientes.